
24 Feb 2024
50
35
In this article, we describe the finetuning experiments we have done to illustrate the effectiveness of SFT and DPO with the public state-of-the-art Mixtral 8x7B model. We start from the pretrained mistralai/Mixtral-8x7B-v0.1. Following HuggingFaceH4/zephyr-7b-beta, we use the publicly available dataset for SFT and DPO training. The datasets involved in this experiment include:
| Dataset | Volumn | |
|---|---|---|
| SFT | UltraChat-200K | 200K |
| DPO | UltraFeedback | 61K |
All experiments are performed with our internally developed distributed training framework based on deepspeed and pytorch_lightning, and are trained with precision bfloat16. We released the SFT and DPO checkpoint:
We perform chat instruction finetuning on Ultrachat-200K dataset, a heavily filtered version of the UltraChat dataset and was used to train Zephyr-7B-β. We used prompt template same as Claude models, i.e. prompt template = "\n\nHuman: {prompt}\n\nAssistant: {response}". The hyperparameters are in the following table. We train for 1 epoch. The released sft checkpoint is https://huggingface.co/vistagi/Mixtral-8x7b-v0.1-sft.
| Model | batch size | lr | optimizer | steps | grad_clip |
|---|---|---|---|---|---|
| SFT | 64 | 5e-5 | adamw | 3200 | 1.0 |
| DPO | 64 | 5e-6 | adamw | 2000 | 10.0 |
We perform DPO training on top of the above SFT on the UltraFeedback dataset, total 61.1K preference pairs. We show the loss curve on the eval set, along with the accuracy and margin on the eval set.
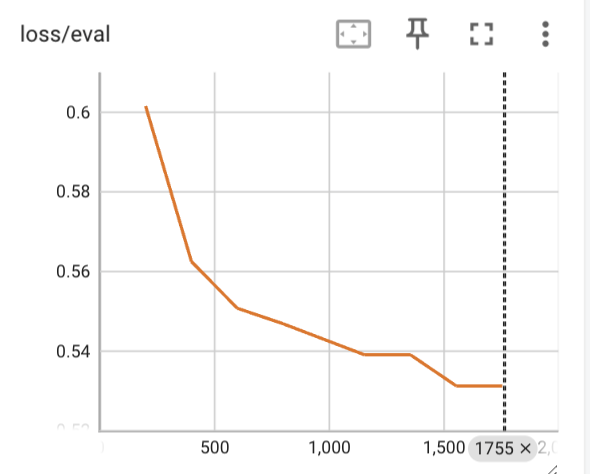
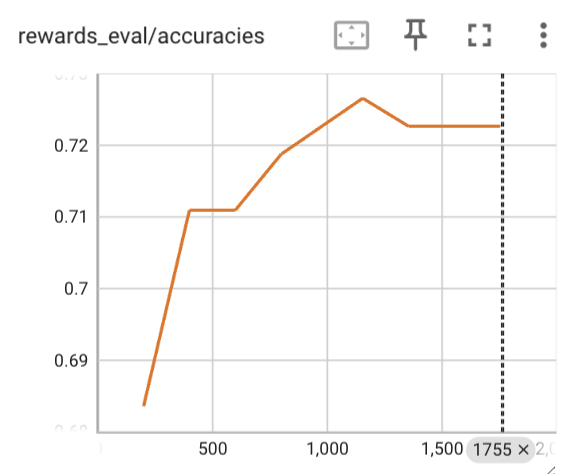
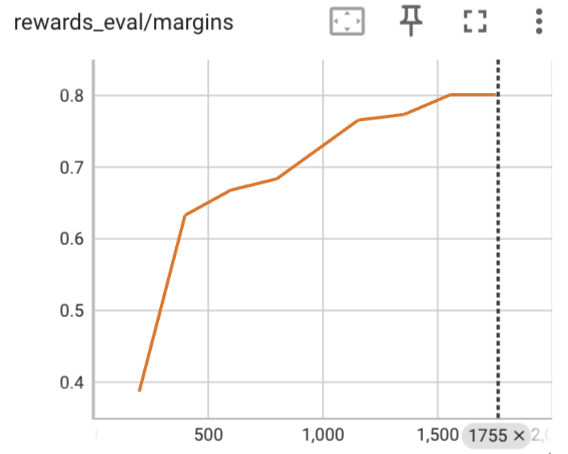
We evaluate the SFT and DPO model on a set of popular LLM benchmarks and compared with pretrained Mixtral model and the public mistral.ai released Mixtral-Instruct model, which is trained using similar methods as we do in this article but the training dataset is unknown. We show the results on the following table.
With the SFT training, the model slightly outperforms the pretrained model. With DPO, the improvement is significant. We are roughly on par with the public Mixtral Instruct model.
| Capability | Benchmark | Eval Type | Mixtral Pretrained | Mixtral SFT | Mixtral DPO | Mixtral Instruct |
|---|---|---|---|---|---|---|
| General | MMLU | multi-choice | 67.76% | 67.21% | 67.94% | 68.79% |
| Reasoning | BBH | generation | 69.39% | 69.16% | 70.08% | 68.16% |
| HellaSwag | multi-choice | 84.09% | 84.05% | 85.18% | 85.97% | |
| Math | GSM8K | generation | 57.62% | 61.79% | 63.38% | 63.91% |
| MATH | generation | 25.86% | 26.70% | 26.44% | 25.48% |